Google Just Dropped Transformer 2.0: Meet "Nested Learning"

Widely known as fotiecodes, an open source enthusiast, software developer, mentor and SaaS founder. I'm passionate about creating software solutions that are scalable and accessible to all, and i am dedicated to building innovative SaaS products that empower businesses to work smarter, not harder.
I’m sitting here with a hot cup of coffee, about halfway through Google’s new paper on "Nested Learning," and I have to be honest: I need to get this out of my head and onto the screen. Usually, when a big lab drops a paper, I skim the abstract, nod at the benchmarks, and move on.
But this one is different. It’s sticking with me.
You know how we’ve been building AI for the last decade? We treat the model’s shape (the architecture) and the way it learns (the optimizer) as two totally different things. You build the house, then you hire a separate crew to paint it. Google just came out and said: "No. The house and the painter are the same thing."
It’s a weird concept to wrap your head around, but once it clicks, it makes the current way we do things look incredibly rigid.
The "goldfish memory" problem
Let's start with the headache we all know: Catastrophic forgetting.
If you take a trained model and try to teach it something new, it tends to overwrite what it already knows. It’s like learning French and suddenly forgetting how to speak English. To fix this, we usually slap on some band-aid solutions, tweaking the architecture or playing with the learning rate.
The Google team, led by Ali Behrouz and Vahab Mirrokni, argues that this happens because we view training as a single, flat process. We shove data in, update weights, and hope for the best.
But the human brain doesn't work like that. We have neuroplasticity. We change our structure based on what we experience. We have layers of memory, some things stick instantly, some take years to solidify. We don't just "update weights"; we run multiple learning processes at different speeds, all at the same time.

The uniform and reusable structure as well as multi-time–scale update in the brain are the key components of continual learning in humans. Nested Learning allows for multi-time–scale updates for each component of the brain, while showing that well-known architectures such as transformers and memory modules are in fact linear layers with different frequency updates (source: research.google/blog)
That’s where nested learning comes in
It’s all just loops
The core idea here is that a machine learning model isn't one big math problem. It’s actually a set of smaller, nested optimization problems.
Imagine Russian nesting dolls, but each doll is a little learning engine with its own job.
In this paradigm, the architecture (like a Transformer) and the optimizer (like Adam or SGD) are fundamentally the same concept. They are just optimization loops running at different frequencies.
Inner loop: this might be the attention mechanism, figuring out the relationship between tokens right now.
Outer loop: this updates the long-term weights of the network.
by admitting that these are just different levels of the same game, you can build systems with "deeper computational depth." You can design components that update fast, slow, or somewhere in between.
"hope"
They didn't just write a theory paper. They built a proof-of-concept architecture called hope.
Hope is a variant of the "Titans" architecture (which is already cool), but it’s self-modifying. It uses something called a Continuum Memory System (CMS). Instead of having just "short-term memory" (the context window) and "long-term memory" (static weights), Hope treats memory as a spectrum(this is actually really cool tbh)
It has modules that update at different rates. This allows it to prioritize memories based on how surprising or useful they are. It’s a self-referential process. The model optimizes its own memory while it learns.
The results they showed are wild(i will add some below, but the full results can be seen in the original paper). Hope beats standard transformers and modern recurrent models on language modeling tasks. But where it really shines is the "Needle-In-Haystack" tests, finding a specific piece of info buried in a massive amount of text. Because it manages memory better, it doesn't get confused by the noise.
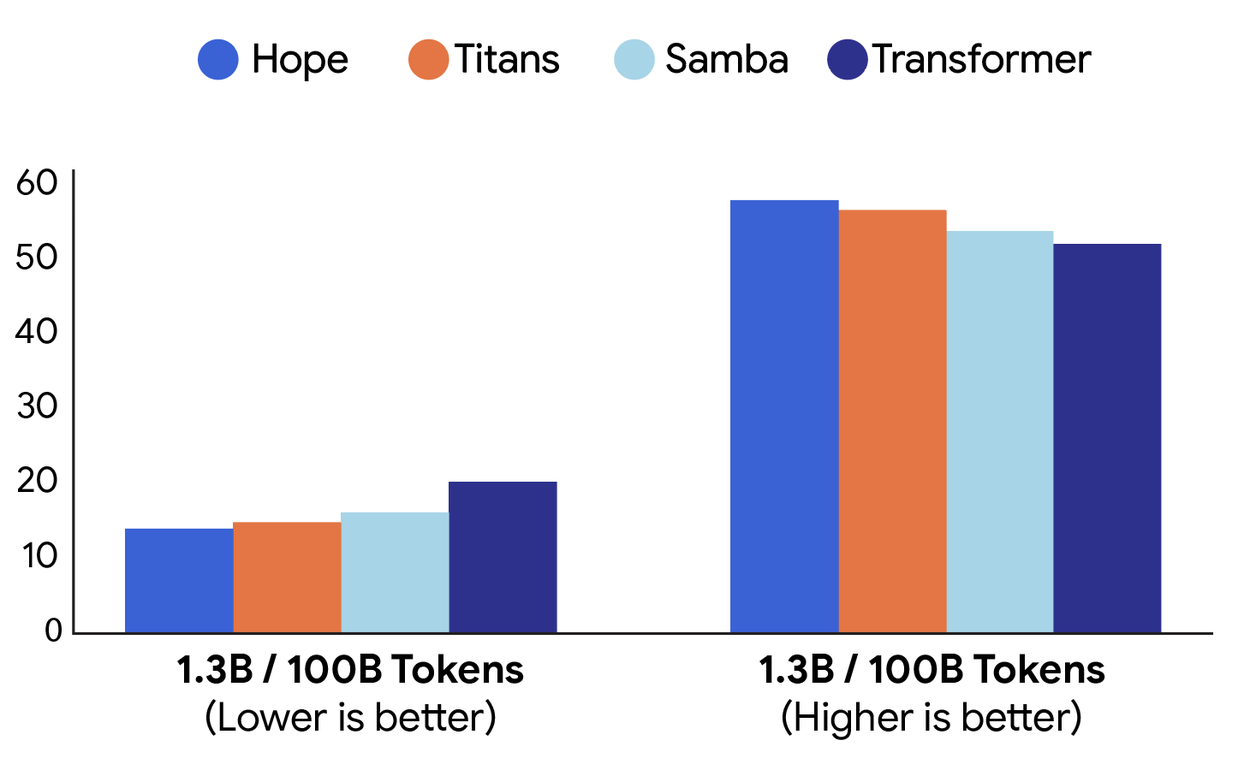
Comparison of performance on language modeling (perplexity; left) and common-sense reasoning (accuracy; right) tasks between different architectures: Hope, Titans, Samba and a baseline Transformer (source: research.google/blog)
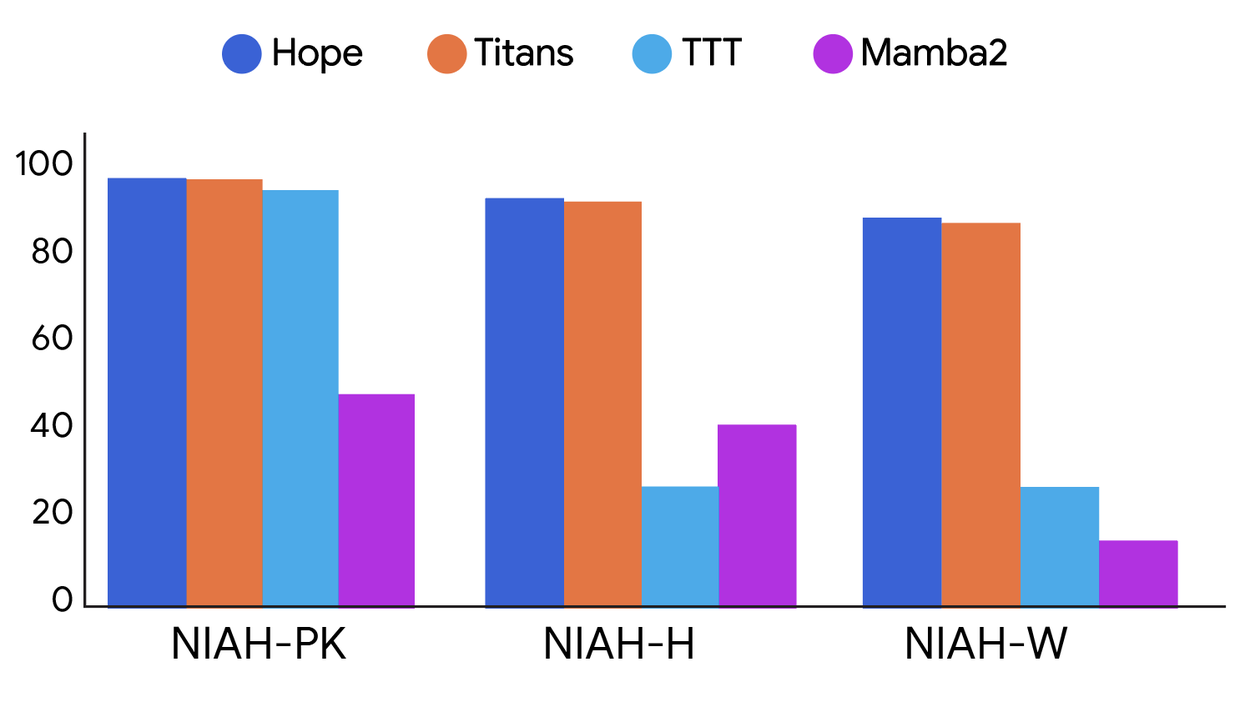
Performance comparison on long-context tasks with different levels of difficulty between different architectures: Hope, Titans, TTT, and Mamba2. NIAH-PK, NIAH-H, and NIAH-W are needle-in-a-haystack tasks with pass-key, number, and word, respectively (source: research.google/blog)
Deep optimizers
Here is the part that made me put my coffee down.
Since they view optimizers as just another layer of memory, they looked at how we currently do optimization. Most standard optimizers use a simple dot-product similarity, basically checking if two vectors point in the same direction.
The researchers realized this is kind of dumb. It doesn't account for how different data samples relate to each other.
So, they swapped the objective. Instead of dot-product, they used L2 regression loss inside the optimizer itself. They call these "Deep Optimizers" By doing this, they derived new versions of momentum that are way tougher when dealing with messy or imperfect data. They essentially applied the principles of associative memory to the math that trains the network.
Why this matters
We are hitting a wall with current LLMs. They are static, they are frozen in time the moment training ends. To make them "learn" we have to cram everything into the context window, which is expensive and temporary.
Nested Learning offers a path to models that actually learn like we do. It’s a shift toward continual learning, a system that can acquire new skills without erasing the old ones, adapting its own structure on the fly.
This feels less like a software patch and more like biology. If "Hope" is any indication, the next generation of models might not just be bigger. They might be alive, in a mathematical sense.
I’m going to go finish the rest of this paper. I have a feeling we're going to see a lot of "Transformer 2.0" headlines soon, but for once, the hype might actually be underplaying the math.