Don’t do RAG: CAG is all you need for knowledge tasks
Understand the distinctions between Retrieval and Cache-Augmented Generation; find out how CAG improves speed while RAG handles real-time information

Widely known as fotiecodes, an open source enthusiast, software developer, mentor and SaaS founder. I'm passionate about creating software solutions that are scalable and accessible to all, and i am dedicated to building innovative SaaS products that empower businesses to work smarter, not harder.
If you have built anything with LLMs recently, you know the pain. You have a model that can write Shakespearean sonnets but doesn’t know your company’s latest shipping policy.
We spent the last year solving this with Retrieval-Augmented Generation (RAG). It became the default setting. But as context windows grow massive and latency becomes the enemy, a new contender has entered the ring: Cache-Augmented Generation (CAG).
I have been working with both. They are often seen as competitors, like you have to choose a side. The reality is that they are just different tools for different constraints.
Here is what you need to know about RAG vs. CAG, how they actually work under the hood, and how to decide which one fits your build.
The old reliable: Retrieval-Augmented Generation (RAG)
RAG is the technique we are all familiar with. It allows the AI to reach outside its training data to grab external information right when it needs it.
Think of RAG like giving the AI a library card. It doesn’t memorize every book in the library. Instead, when you ask a question, it runs to the shelves, grabs the specific pages it needs, and uses them to write an answer.
How it works
The workflow is standard by now:
Ingestion: You break your documents into chunks (usually 100 to 1,000 tokens).
Retrieval: When a user queries the system, we turn that query into a vector and search a vector database for the most relevant chunks.
Generation: We feed those chunks into the LLM as context to generate the answer.
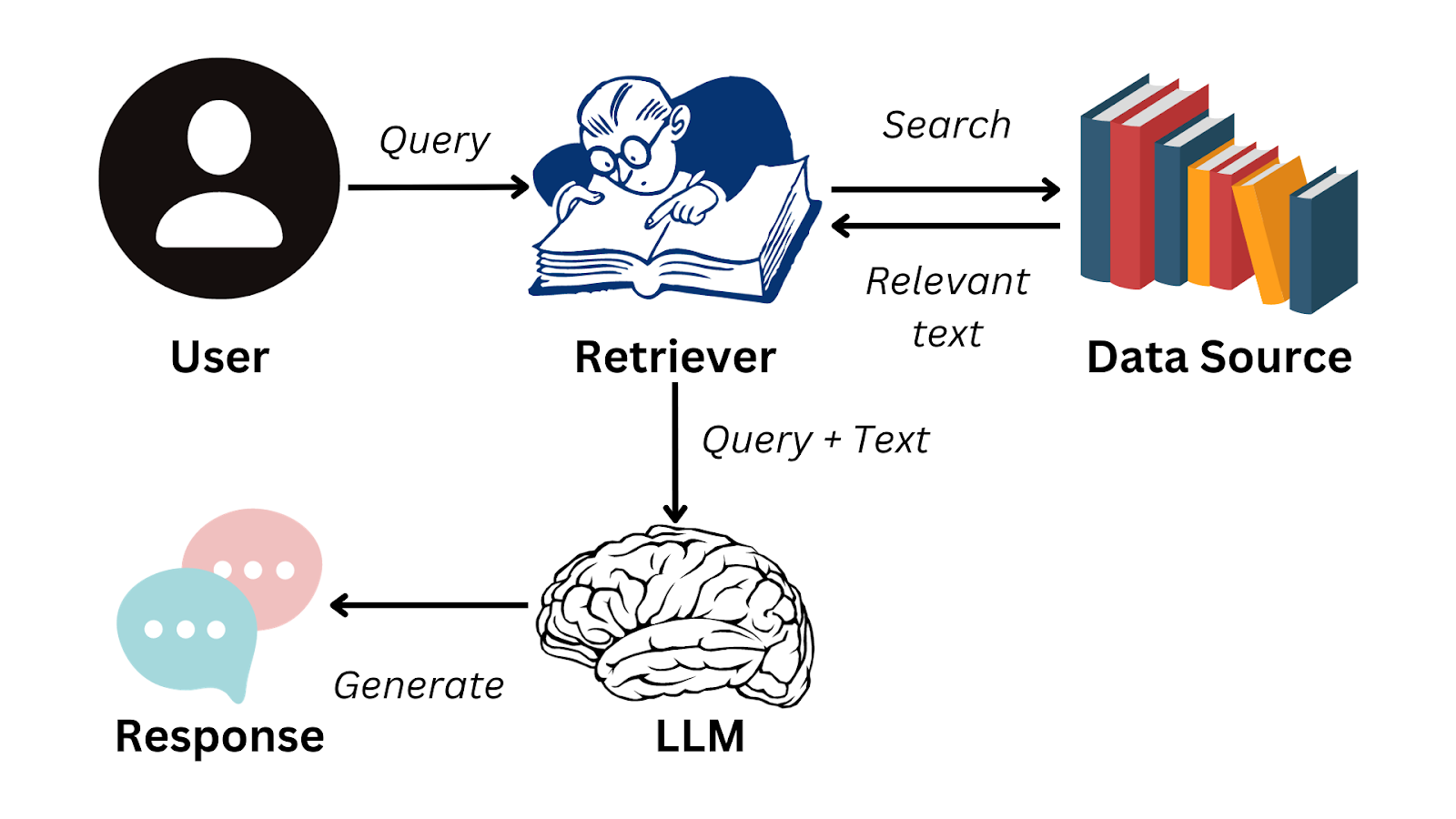
Typical rag workflow
Why we use it
I like to see RAG as the king for freshness. If your legal team updates a policy at 3:00 pm, a RAG system can cite that new policy at 3:01 pm without any retraining. It excels at handling massive datasets, scientific papers, case law, or proprietary databases that are far too large to fit into a context window.
It also helps with the lying problem. By forcing the model to look at retrieved documents, we anchor the output to facts, which cuts down on hallucinations.
The trade-off
The cost here is complexity and speed. You have to manage a vector database and an embedding pipeline. Every query has to go through a retrieval step before the LLM even starts thinking. That adds latency. If your retrieval logic is bad, your answers will be bad for sure.
The challenger: Cache-Augmented Generation (CAG)
CAG is the newer approach, and it took me a minute to see the value. But once you see it, the elegance is obvious.
Following the library analogy we used earlier, if RAG is a library card, CAG is a cheat sheet you prepared the night before. You don't run to the library for every question; you have the answers right there in front of you.
How it works
CAG takes advantage of the massive context windows we see in modern models (sometimes millions of tokens). Instead of fetching data dynamically, we preload the relevant knowledge into the model’s context or cache memory.
It relies on two mechanisms:
Knowledge caching: Loading the documents into the extended context window once.
Key-value (KV) caching: Storing the attention states (the math the model does while processing tokens).
So when a new query comes in, the model doesn't re-read the documents. It reuses the pre-calculated states.
Why we use it
Speed. Because the model reuses cached computations, the response time drops like a rock. It is incredibly efficient for repetitive queries or situations where the context doesn't change much during a conversation.
It also simplifies the stack. You don't need a vector database lookup for every single turn of the conversation.
The trade-off
The problem is staleness. If the data changes, your cache is wrong until you refresh it. Also, you are bound by memory. Maintaining a large cache requires serious RAM. You can't just cache the entire internet like you can index it with RAG.
Head-to-head: The technical differences
When you are architecting a system, you need to look at the constraints. Here is how they stack up.
Latency: CAG wins. It accesses info from memory. RAG has to search, retrieve, and process before it generates.
Freshness: RAG wins. It’s real-time. CAG is a snapshot; it’s only as fresh as the last cache update.
Scalability: RAG scales horizontally with your database size. CAG is memory-bound by the context window and available RAM.
Consistency: CAG provides a very consistent experience across a session because the context is static.
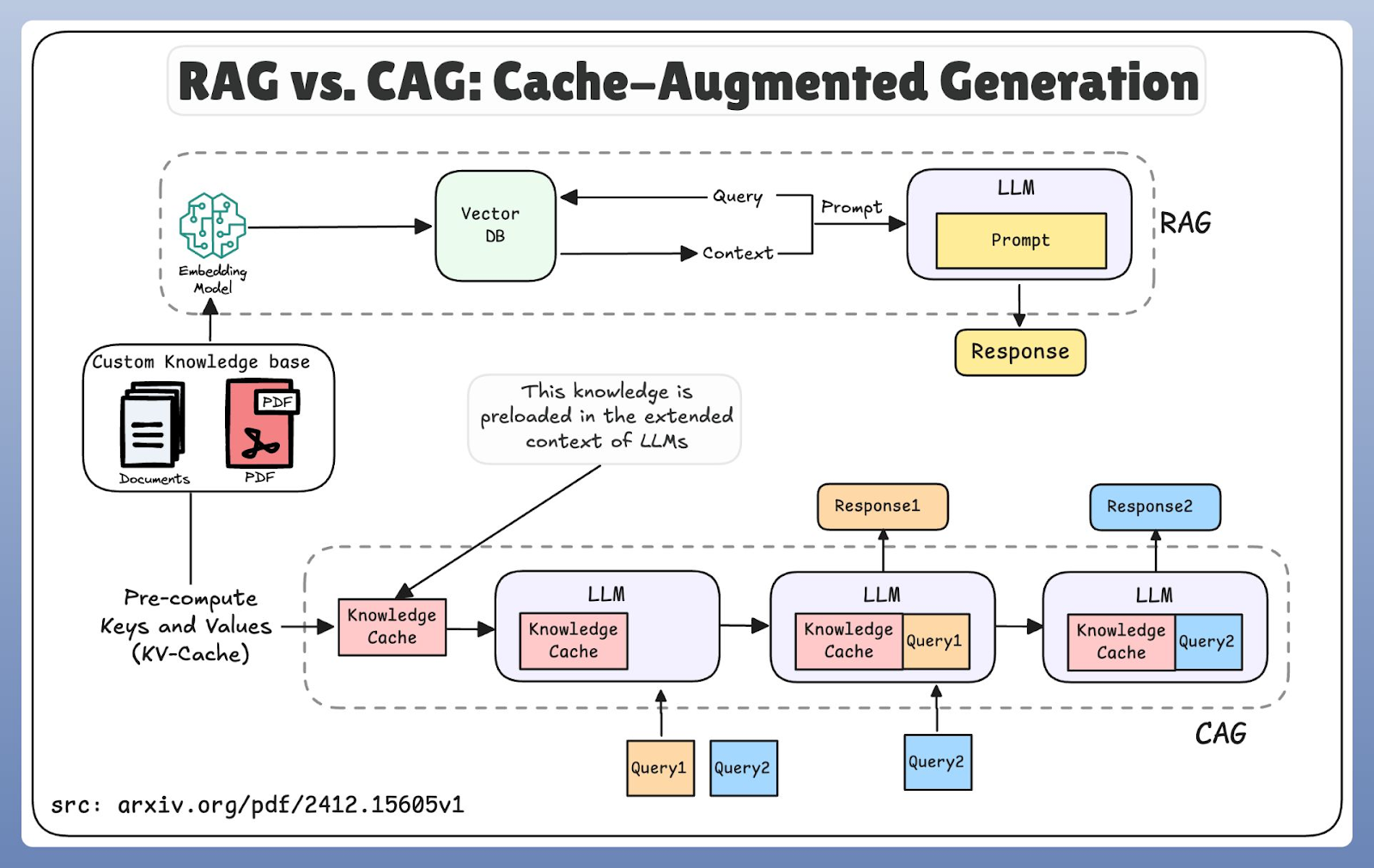
RAG and CAG workflow comparison
Which one should you build?
I get asked this constantly. The answer depends on your specific constraints regarding data volatility and query volume.
Use RAG if:
Your data changes constantly. If you are building a news analysis bot or a stock market advisor, you can't afford stale data.
Your dataset is massive. If you have terabytes of legal archives, you can't fit that in a context window.
You need citations. RAG makes it very easy to point to the specific document that generated the answer.
Use CAG if:
Your data is stable. Think HR policies, standard operating procedures, or compliance rules that change once a year.
You have repetitive queries. If you are answering the same 100 questions all day, CAG is far more efficient.
Latency is critical. If you are building a real-time voice agent or a gaming NPC, the retrieval lag from RAG will kill the experience for sure.
Real world applications
Let's look at where these fit in actual production environments.
Healthcare: This is often a hybrid case. You might use CAG for standard diagnostic protocols that haven't changed in ten years (speed and consistency). But you would swap to RAG to look up the latest drug interaction research published yesterday.
Finance: Here, the risk of being wrong is high. Financial institutions usually lean toward RAG for compliance monitoring and market analysis because the regulatory environment shifts daily. However, for internal FAQs about standard banking products, CAG is faster and cheaper.
Coding: For software engineers, RAG is great for fetching documentation from libraries that update weekly. But for code autocompletion where speed is everything, CAG is the standard. It caches the patterns and context of the current file to predict the next line instantly.
Legal: CAG is excellent for checking contracts against a fixed set of "Anti-Bribery Guidelines." You load the guidelines once, and check every contract against them. But for case law research? That is RAG territory. You need access to the entire history of court decisions.
The hybrid approach
In production, you rarely stick to just one. The industry is moving toward hybrid architectures.
You use CAG to handle the high-volume, static stuff (like the "Welcome" message or standard FAQs). Then, you route the tricky, dynamic queries to a RAG pipeline. This gives you the speed of caching for 80% of your traffic, and the accuracy of retrieval for the complicated 20%.
The complexity here is orchestration, knowing when to route to the cache and when to trigger a search. But if you can pull it off, it is for sure the best of both worlds.
Final thoughts
In my opinion, don't overcomplicate it. If you are worried your model is going to give outdated answers, start with RAG. You can optimize for speed later. If you have a defined, stable set of documents and you need the bot to be lightning-fast, look at CAG.
The goal isn't to use the coolest acronym. It's to get the right context to the model at the right time. Choose the tool that fits the job.