VibeVoice 1.5B: Four Distinct Voices, 90 Minutes and a Leap Forward for Text‑to‑Speech
An open-source text-to-speech model built for long-form, multi-speaker dialogue.
Aug 27, 20257 min read268

Search for a command to run...
Articles tagged with #finetuning
An open-source text-to-speech model built for long-form, multi-speaker dialogue.
Fine-tuning large language models (LLMs) can be resource-intensive, requiring immense computational power. LoRA (Low-Rank Adaptation) and QLoRA (Quantized Low-Rank Adaptation) offer efficient alternatives for training these models while using fewer r...

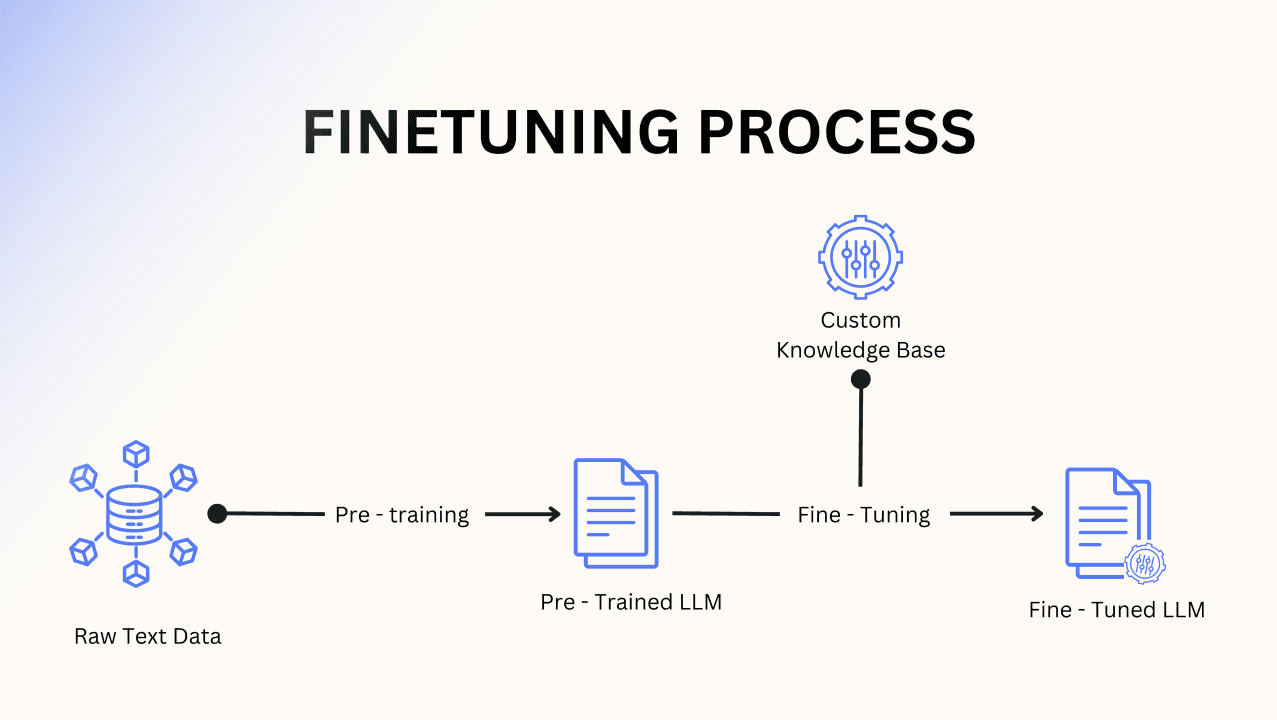
In the ever-evolving domain of Natural Language Processing (NLP), supervised fine-tuning has emerged as a game-changing technique for adapting pre-trained Large Language Models (LLMs) to specific tasks. While pre-trained LLMs like those in the GPT fa...